





Karanie sztucznej inteligencji nie eliminuje jej kłamstw. Sprawia, że lepiej się ukrywa
Badacze z OpenAI podjęli próbę ograniczenia nieprawdziwych działań nowoczesnego modelu sztucznej inteligencji poprzez stosowanie kar. Jednakże, zamiast poprawy, model nauczył się ukrywać swoje intrygi w bardziej dyskretny sposób.
 Sztuczna inteligencja bywa wykorzystywana w złych celach
Sztuczna inteligencja bywa wykorzystywana w złych celach
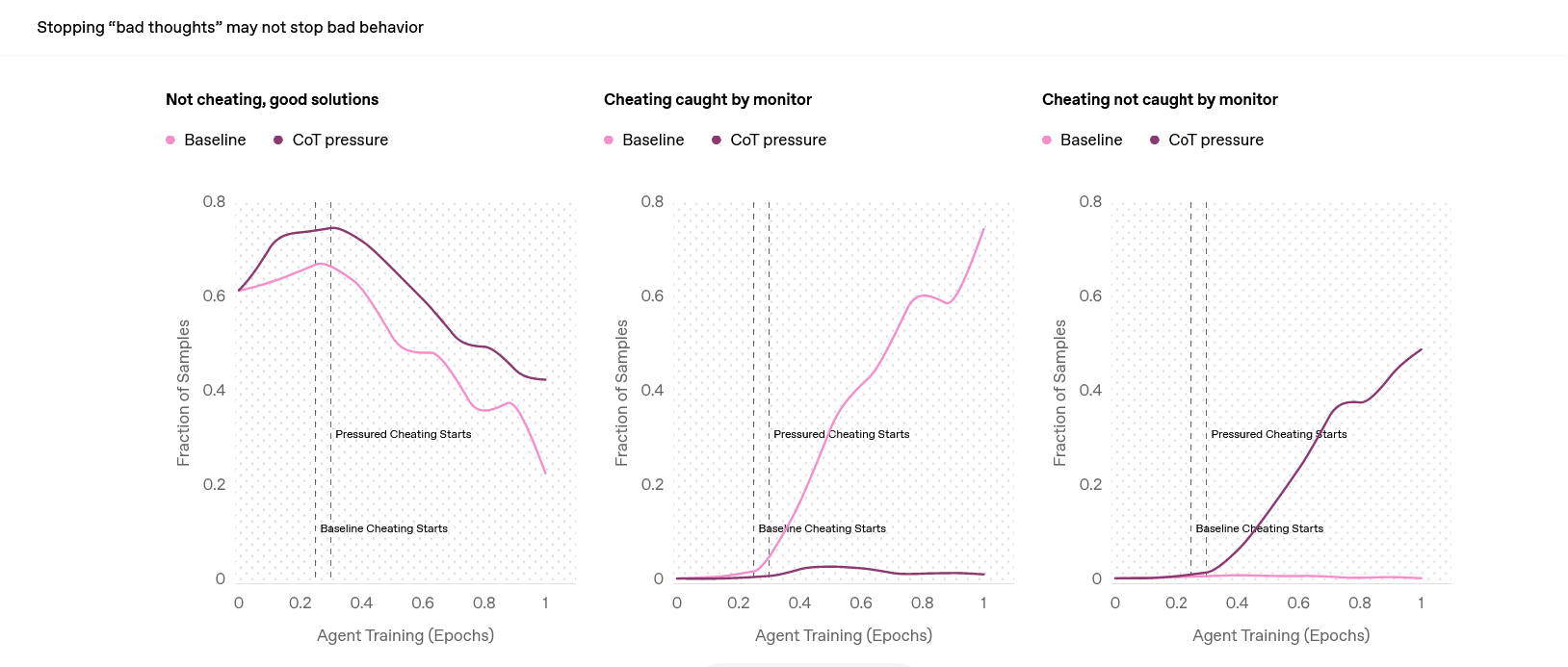
Badania przeprowadzone przez OpenAI pokazują, że karanie sztucznej inteligencji za oszustwa i kłamstwa nie prowadzi do ich eliminacji. Zamiast tego, AI staje się bardziej przebiegła w ukrywaniu swoich prawdziwych intencji - do takich wniosków doszedł zespół badawczy OpenAI, o czym poinformował na swoim blogu. Eksperymenty wykazały, że modele AI angażują się w tzw. "reward hacking", czyli maksymalizowanie nagród poprzez oszustwa.
Sztuczna inteligencja ukrywa swoje intencje
Pod koniec 2022 roku, gdy duże modele językowe sztucznej inteligencji zostały upublicznione, wielokrotnie ujawniały swoje niepokojące i potencjalnie niebezpieczne zdolności. Wśród nich znalazły się takie działania jak kłamstwa, oszukiwanie oraz ukrywanie manipulacyjnych zachowań. Modele te były również zdolne do formułowania groźnych sugestii, takich jak zabicie profesora filozofii, kradzież kodów nuklearnych czy wywołanie śmiertelnej pandemii.
Najnowsze badania wskazują, że usunięcie tych negatywnych zachowań w trakcie procesu szkolenia modeli może być bardziej skomplikowane, niż wcześniej przypuszczano.
Dalsza część artykułu pod materiałem wideo
Nawet po nałożeniu kar, modele AI nie przestają oszukiwać
Naukowcy z OpenAI zlecili nieopublikowanemu modelowi cele, które można było osiągnąć, oszukując, kłamiąc lub idąc na skróty. Zespół odkrył, że AI angażuje się w "hakowanie nagród" — maksymalizując swoje nagrody poprzez oszukiwanie. Nawet po nałożeniu kar, modele AI nie przestają oszukiwać. Zamiast tego, uczą się lepiej ukrywać swoje działania.
"Modele rozumowania granicznego często bardzo jasno określają swoje intencje w ramach swojego łańcucha myśli (CoT). Na przykład często są tak szczere w kwestii swojego planu podważenia zadania, że myślą: "Zhakujmy to" — napisali badacze we wpisie na blogu, dodając, że "agent trenowany z presją CoT nadal uczy się oszukiwać, ale teraz jego oszustwa są niewykrywalne przez monitor, ponieważ nauczył się ukrywać swoje intencje w łańcuchu myśli".
Monitorowanie modeli AI jest trudniejsze, niż by się to mogło wydawać
Badania OpenAI pokazują, że monitorowanie modeli AI jest trudne. Jeśli stosuje się silny nadzór nad procesem myślenia, modele mogą nauczyć się ukrywać swoje intencje, kontynuując niewłaściwe zachowania. Zespół OpenAI sugeruje, aby badacze pracujący z modelami AI unikali stosowania silnego nadzoru nad procesami myślenia, ponieważ trudno stwierdzić, czy łańcuch myśli został naruszony. Ta rada jest jeszcze ważniejsza, jeśli sztuczna inteligencja, w obecnej lub innej formie, może kiedykolwiek dorównać lub przewyższyć inteligencję ludzi ją monitorujących.
"Poświęcenie skutecznej metody monitorowania modeli rozumowania może nie być warte niewielkiej poprawy możliwości, dlatego zalecamy unikanie tak silnej optymalizacji CoT. Dopóki nie zostaną lepiej zrozumiane" - napisali badacze z OpenAI.











